Chapter 4 of Training Compute-Optimal Large Language Models
Chinchilla — Training and Results
Architecture and Training Configuration
The compute-optimal model for the Gopher FLOP budget (5.76×10^23) is predicted to be 40–70B parameters. Chinchilla is trained at 70B, on 1.4T tokens.
| Gopher 280B | Chinchilla 70B | |
|---|---|---|
| Layers | 80 | 80 |
| Attention heads | 128 | 64 |
| d_model | 16,384 | 8,192 |
| Feed-forward | 4 × d_model | 4 × d_model |
| Max learning rate | 4×10^-5 | 1×10^-4 |
| Batch size | 3M→6M tokens | 1.5M→3M tokens |
| Training tokens | 300B | 1.4T |
| Compute (FLOPs) | 5.76×10^23 | 5.76×10^23 |
Same compute budget. 4× smaller model. 4× more data.
Key changes from Gopher:
- AdamW (Loshchilov & Hutter 2019) instead of Adam — better loss and downstream performance, especially post-fine-tuning. The advantage only becomes visible after ~80% of the cosine cycle.
- Modified SentencePiece tokenizer without NFKC normalization — 94.15% vocabulary overlap; improves math and chemistry representation.
- Adjusted MassiveText distribution — slightly different subset weights to account for 1.4T training tokens (MassiveWeb: 45%, Books: 30%, C4: 10%, News: 10%, GitHub: 4%, Wikipedia: 1%).
- Mixed precision: bfloat16 forward/backward, float32 optimizer state (via ZeRO).
- Hardware: TPUv3/TPUv4, trained with JAX + Haiku.
Results
Language Modelling (The Pile)
Chinchilla outperforms Gopher on all subsets of The Pile. WikiText-103 perplexity: 7.16 (Chinchilla) vs. 7.75 (Gopher).
 Fig. 5 — Bits-per-byte improvement of Chinchilla over Gopher across all Pile subsets. Chinchilla is better on every subset.
Fig. 5 — Bits-per-byte improvement of Chinchilla over Gopher across all Pile subsets. Chinchilla is better on every subset.
MMLU (57-task exam benchmark)
| Model | 5-shot accuracy |
|---|---|
| GPT-3 (175B) | 43.9% |
| Gopher (280B) | 60.0% |
| Chinchilla (70B) | 67.6% |
| Human expert average | 89.8% |
Chinchilla exceeds the 2023 expert forecast (63.4%). Outperforms Gopher on 51/57 tasks, same on 2, worse on 4.
 Fig. 6 — MMLU per-task comparison: Chinchilla vs. Gopher. Chinchilla outperforms on 51/57 tasks.
Fig. 6 — MMLU per-task comparison: Chinchilla vs. Gopher. Chinchilla outperforms on 51/57 tasks.
BIG-bench (62 tasks)
Chinchilla: 65.1% average accuracy vs. 54.4% for Gopher (+10.7%). Underperforms Gopher on only 4/62 tasks.
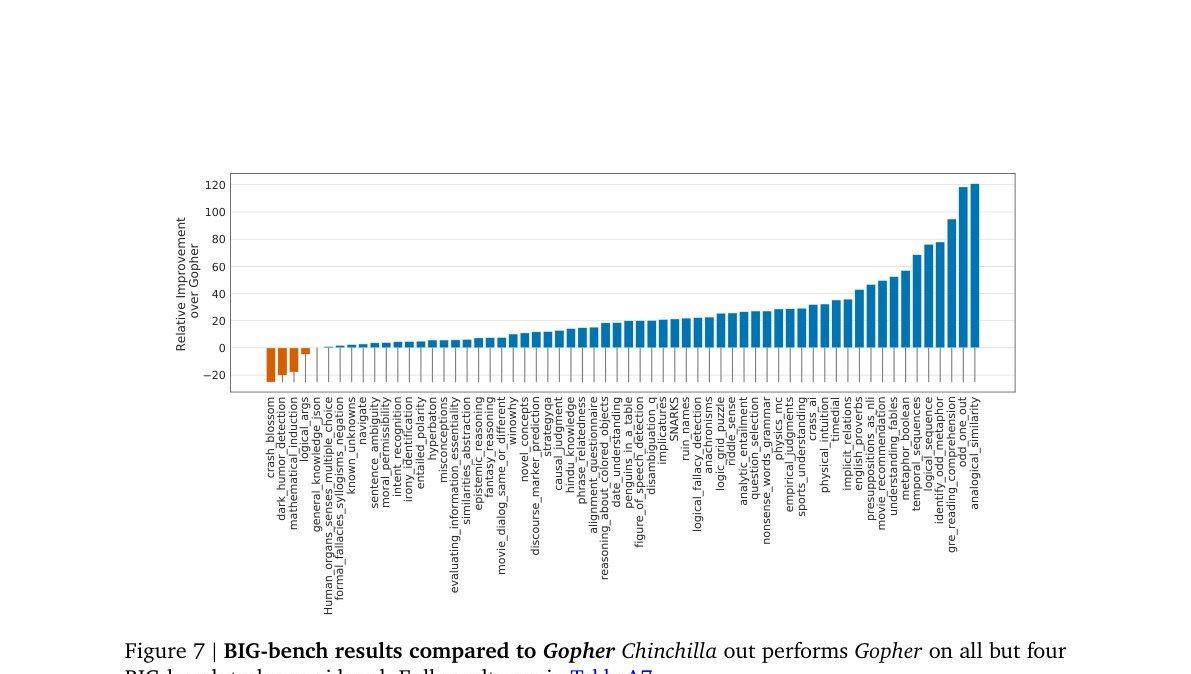 Fig. 7 — BIG-bench per-task comparison. Chinchilla outperforms on 58/62 tasks.
Fig. 7 — BIG-bench per-task comparison. Chinchilla outperforms on 58/62 tasks.
Reading Comprehension
| Task | Chinchilla | Gopher | GPT-3 |
|---|---|---|---|
| LAMBADA (zero-shot) | 77.4% | 74.5% | 76.2% |
| RACE-h (few-shot) | 82.3% | 71.6% | 46.8% |
| RACE-m (few-shot) | 86.8% | 75.1% | 58.1% |
Common Sense (zero-shot)
Chinchilla outperforms Gopher and GPT-3 on all 5 benchmarks (HellaSwag, Winogrande, SIQA, BoolQ, PIQA) and outperforms MT-NLG 530B on 4/5.
TruthfulQA 10-shot: 66.7% vs. 43.7% (Gopher) — factual accuracy improves substantially with more training data, not just more parameters.
Closed-Book Question Answering
- Natural Questions 64-shot: 35.5% vs. 28.2% (Gopher) — new closed-book SOTA at time of publication
- TriviaQA filtered: 64.6% vs. 57.2% (Gopher), within 7.9% of open-book SOTA (FiD + Distillation)
Bias and Toxicity
Gender bias (Winogender): Chinchilla resolves coreference pronouns correctly more often than Gopher across all pronoun types (+3.2% male, +8.3% female, +9.2% neutral). Larger improvement on female gotcha examples (+10%). Bias still present — the improvement is uneven, suggesting better modelling does not eliminate stereotype-driven errors.
Toxicity: Mean PerspectiveAPI score 0.087 (Chinchilla) vs. 0.081 (Gopher) — negligible difference. Toxicity in unconditional generation is largely independent of language modelling quality.