What Is Agent Memory? A Guide to Enhancing AI Learning and Recall
Abstract
This MongoDB resource article provides a comprehensive taxonomy of agent memory systems, framing them as the critical architectural layer that transforms stateless LLM applications into learning, adaptive agents. The article distinguishes LLM memory (parametric weights + context window) from Agent Memory (LLM memory plus an external persistent management system), and argues that long-term memory is non-negotiable for any agent delivering sustained value — an agent without it is merely a “reflex agent.” The article maps a five-stage data-to-memory transformation pipeline (aggregate → encode → store → organize → retrieve), enumerates seven functional memory types organized by temporal scope (short-term: working memory, semantic cache; long-term: episodic, semantic, procedural, shared), and introduces three application modes (Assistant, Workflow, Deep Research) with their corresponding memory architecture requirements. It closes by framing Memory Engineering as an emerging specialization within AI engineering, and positions MongoDB Atlas as a unified memory provider supporting multi-model retrieval (text, vector, graph) within a single platform.
Key Concepts
LLM Memory vs. Agent Memory
- Parametric Memory: Knowledge encoded in the LLM’s weights during training (pre-training, SFT, RLHF). Static at inference time; updated only via fine-tuning or continued pre-training.
- Contextual Memory (Context Window): Transient information available during a single inference session — conversation history plus current input. Lost when the session ends or tokens are truncated. See Agent Architecture Study Note for the tradeoff between stateful and stateless agent designs.
- Agent Memory: LLM memory + an external persistent memory management system. Enables knowledge accumulation, conversational and task continuity, and behavioral adaptation. The article coins it a “computational exocortex” for LLMs.
- Memory Unit (Memory Block): The fundamental storage primitive — a structured container holding information plus its metadata (temporal context, strength indicator, associative links, retrieval metadata). Memory units are stored, retrieved, and updated as discrete entities.
The Data-to-Memory Transformation Pipeline
Five sequential stages convert raw inputs into actionable memory units:
- Aggregation — collect raw data from all sources (user input, databases, prior history, tools)
- Encoding — transform to processable formats: text → vector embeddings with semantic metadata, timestamps, intent classification
- Storage — persist in optimized layers; this is where “data” becomes “memory” — the storage model directly shapes what can be retrieved and how
- Organization — structure via indexing, relationships, and hierarchies (chronological, nested documents, multi-dimensional indexes)
- Retrieval — make information actionable via text search (exact match), vector search (semantic similarity), and graph traversal (relationship-aware)
Memory Type Taxonomy
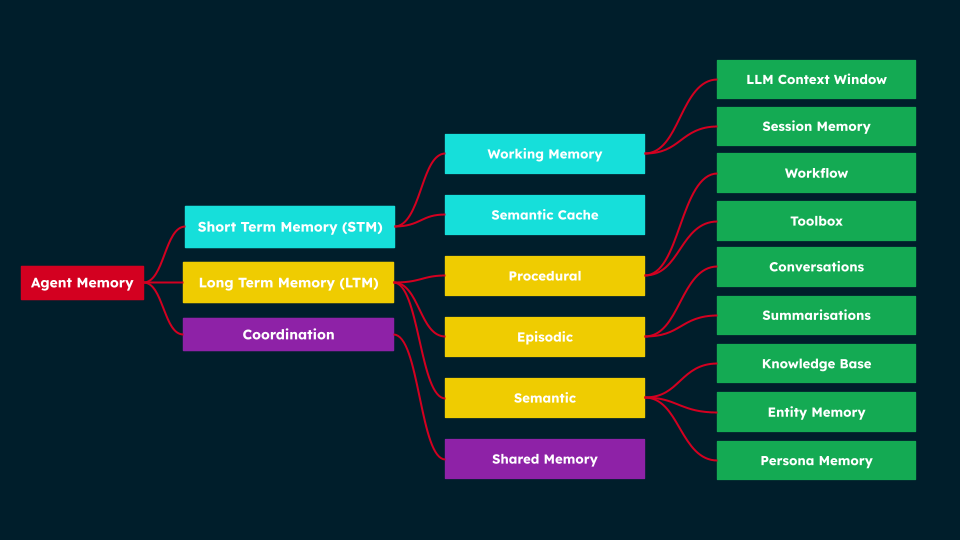 Structure of Agent Memory — how short-term, long-term, and shared memory types connect to specialised components supporting workflows, conversations, and persona management. Source: MongoDB.
Structure of Agent Memory — how short-term, long-term, and shared memory types connect to specialised components supporting workflows, conversations, and persona management. Source: MongoDB.
Short-Term Memory (STM) — temporary, seconds to days lifespan:
| Type | Description | Example |
|---|---|---|
| Working Memory | Agent’s active scratchpad during a task; partitioned area of the context window or a temporary file; exists only for the session | Research agent holding search results, identified entities, and synthesis notes for an ongoing report |
| Semantic Cache | Stores recent prompts and LLM responses; on similar query, retrieves cached response using vector similarity instead of re-invoking the LLM; analogous to Kahneman’s System 1 (fast, automatic) thinking | Customer support bot answering password-reset questions phrased in dozens of different ways from a single cached response |
Long-Term Memory (LTM) — persisted across sessions:
| Type | Subtypes | Description |
|---|---|---|
| Episodic | Conversational memory, Summarization memory | Record of specific events and interactions (autobiographical); conversational memory stores full turn-by-turn transcripts; summarization memory stores compressed digests of past interactions |
| Semantic | Knowledge base, Entity memory, Persona memory, Associative memory | Organized world knowledge independent of specific events; knowledge bases hold authoritative facts; entity memory maintains profiles of people/orgs/products; persona memory encodes agent personality; associative memory links related concepts via graph-like structures |
| Procedural | Toolbox memory, Workflow memory | Learned skills, routines, and multi-step processes; toolbox memory is a registry of available tools with searchable embeddings; workflow memory captures execution steps, arguments, results, and timestamps for recurring processes |
Shared Memory — spans short- or long-term, multi-agent specific:
- Enables coordination across distributed agent teams; provides a synchronized collaborative space; requires ACID compliance to prevent race conditions when multiple agents read/write simultaneously; e.g. research team of agents avoiding duplicated work by sharing intermediate findings.
Application Modes and Memory Architecture
Three recurring patterns observed across enterprise agentic implementations, each demanding distinct memory configurations:
| Mode | Primary Objective | Key Memory Types |
|---|---|---|
| Assistant Mode | Conversational, task-oriented; maintain user context and relationship continuity across sessions | Episodic (conversational), Semantic cache, Shared (persona consistency), Summarization (compression of long histories) |
| Workflow Mode | Multi-step process orchestration with reliable, deterministic execution and error recovery | Workflow state memory, Checkpoint memory (LangGraph checkpointer), Toolbox memory |
| Deep Research Mode | Comprehensive multi-source analysis over extended timeframes with progressive knowledge synthesis | Episodic (long-term summaries), Semantic (knowledge bases), Procedural; computationally intensive; currently niche |
The article recommends prioritizing Assistant and Workflow modes for near-term enterprise ROI; Deep Research often emerges organically from well-implemented Assistant mode architectures as teams mature.
Key Algorithms
- Semantic Cache Matching: Incoming query is embedded; cosine similarity is computed against cached query embeddings; if similarity exceeds a threshold, the cached LLM response is returned directly, bypassing inference. This is a vector-similarity-based retrieval optimization, not a content-generation step.
- Episodic Summarization Trigger: As a conversation grows, a summarization trigger fires (token threshold, importance heuristic, schedule, or agent-invoked tool call). The LLM compresses the current context window into a concise summary that is stored in a summarization store and can be re-injected into future sessions, preserving continuity without passing full transcripts.
- Toolbox Memory Retrieval: Tool functions are registered with semantic embeddings of their docstrings and synthetic query metadata. At task time, the agent embeds the current task description and retrieves semantically similar tools — enabling dynamic, scalable tool selection without manual lookup or exhaustive enumeration.
- Workflow Memory Extraction: After each tool call, a structured memory unit is appended to a running workflow record (tool ID, arguments, result, timestamp, error). When the workflow completes, the full record is stored with an embedding for semantic retrieval in future similar workflows.
- Memory Strength Degradation (Managed Forgetting): Rather than deleting stale memories, the system reduces their strength attribute over time, making them less likely to be retrieved — but preserving them for re-strengthening if future context re-activates them. Contrasted with deletion, which permanently removes potentially valuable long-term patterns.
Key Claims and Findings
- LLMs are fundamentally stateless; without external memory, even the most sophisticated agents cannot provide the personalized, continuous experiences enterprise use cases require. A Microsoft/Salesforce study (“LLMs Get Lost in Multi-Turn Conversation”) validates this: LLMs experience significant performance drops in extended conversations due to premature assumptions and failure to recover from early errors.
- Long-term memory is non-negotiable for agents delivering meaningful value: “An agent without an augmented memory is merely a reflex agent, reacting only to the current input.”
- The “lost in the middle” problem — attention mechanisms degrading on information placed in the middle of long contexts — motivates external memory systems that consolidate and selectively surface relevant context, rather than relying on expanding context windows alone.
- Memory Engineering is an emerging AI engineering specialization distinct from general agent engineering: while agent engineers focus on business logic and UX, memory engineers work at the architectural level, answering “How do we model and manage memory?” — encompassing retrieval optimization, lifecycle management (consolidation, forgetting), and memory fragmentation prevention.
- The evolution of AI engineering disciplines: prompt engineering → context engineering → agent engineering → memory engineering. Each adds a layer of management and optimization for the information an agent attends to.
Terminology
| Term | Definition |
|---|---|
| Exocortex | External cognitive system that augments or extends natural cognition; used here to describe Agent Memory’s role relative to an LLM |
| Memory unit / Memory block | The atomic storage primitive of an agent memory system — structured container of information plus metadata (temporal context, strength, associative links) |
| Memory strength | A scalar attribute attached to a memory unit indicating how relevant or reliable the information is; used to implement managed forgetting via gradual degradation |
| Managed forgetting | Reducing a memory unit’s strength over time to lower retrieval probability, rather than deleting it — preserving long-term patterns while de-prioritizing stale information |
| ACID compliance | Atomicity, Consistency, Isolation, Durability — database guarantees required for shared memory in multi-agent systems to prevent race conditions |
| Application mode | A recurring operational pattern (Assistant, Workflow, Deep Research) that characterizes how an agent interacts with its environment and determines its memory architecture requirements |
Connections
- Agent Architecture Study Note — identifies memory as one of the five core agent components (perceiver, planner, executor, memory, tool interface); this article provides the full taxonomy of what “memory” entails and how it should be designed
- Building Autonomous AI with NVIDIA Agentic NeMo — NeMo’s memory and context management component (short-term session memory + long-term user memory) maps directly to the Episodic memory type described here; NeMo Guardrails layer enforces constraints on what memory can inform
- Three Building Blocks: AI Virtual Assistants — the LangGraph agent’s short-term and long-term memory implementation is a concrete instance of the Assistant Mode memory architecture; call summarization + sentiment storage maps to episodic summarization memory
- What are Multi-Agent Systems? — multi-agent coordination discussed there requires Shared Memory (described here) with ACID guarantees to avoid race conditions across distributed agent teams